Dead simple core.async job system in Clojure
In my off time (and my on time, for that matter) I've been working on this quirky thing I've called Scinamalink (sounds like 'skinamarink'). Scinamalink lets customers send Magic login links to their users with a single REST API call. If you don't know what a magic login link is, it's basically a password reset email on steroids. Quite literally a link that just authenticates the user's session, skipping the usual password reset flow.
My motivations for working on Scinamalink range from having something to show off my Clojure skills on Twitch, and to see if this is worthwhile for people since services like Auth0 and Clerk support magic login links. I'm 'unbundling' as the cool kids say.
An early problem I was concerned with was curtailing spam. I figure the best approach for this would be domain verification for the customer's domain. Makes sense. Time for an asynchronous job and some DNS queries.
Avoiding a RabbitMQ hole
The first thing someone suggested was introducing some kind of message broker, like RabbitMQ, and going from there. I said hell no. I'm trying to avoid complexity. Yet, I understand that building an async worker from scratch doesn't seem like the simplest approach.
My line of thinking is this: I think infrastructure is part of your Software Architecture. Every component in an architecture adds exponentially more complexity, whether it's a software component, or another process on the same network. By using something like RabbitMQ and writing the jobs for it, I'm essentially adding two or three more components to the architecture: The RabbitMQ process, its deployment configuration, and the code to manage jobs from my main application server.
Such complexity may be worth it for some developers building a solution, but, as someone who wants to get to market faster, cutting the ops work looks like the better approach. The obvious trade-off being my single-process worker system may be less reliable than RabbitMQ.
Simple Yet Reliable Enough
I have a single process with multiple threads, thanks to core.async. It's not lost on me that if the process fails, the jobs will be lost, so my approach to reliability starts at the data model and database. Let's take a look at the PostgreSQL data definition for a job:
CREATE TYPE worker_job_state AS ENUM ('created', 'starting', 'working', 'finished', 'crashed');
CREATE TABLE IF NOT EXISTS worker_jobs (
id serial primary key,
current_state worker_job_state not null default 'created',
timeout timestamp default now() + interval '24 hours',
attempt_count integer not null default 0,
priority integer not null default 1,
context jsonb not null,
created_at timestamp not null default now(),
updated_at timestamp not null default now()
);I originally intended for timeouts and priorities to be a thing, but they're 'reserved for future use' (waste of time). But, since each job could be different in implementation, it's necessary to store some of the context in a free-form JSON blob column. For example, when verifying domain ownership, it might be a good idea to store the customer and domain associated with the verification job.
However, we can see each job shares the same states describing the job's lifecycle: created, starting, working, finished, and crashed. I think each state is self-explanatory here, and these states imply each job function is a Finite-State-Machine (FSM).
All work, no play
So, I need to implement a Finite-State-Machine in Clojure. If you've read any of my previous works, you know whats coming next: Functions returning functions. In short, we can implement a finite state machine by having a function represent each state. When a state needs to transition to another state, it returns that function, otherwise it returns itself. We can use the recurring lexical scope in a recursion to propel the state machine forward. It might be easier to start with the loop:
;; in scinamalink.core.worker namespace
(def buffer-limit (or (:job-buffer-limit env) 2048))
(defonce queue (a/chan (warning-dropping-buffer
buffer-limit
"job queue full, job dropped")))
(defn worker
"Spins off a go-loop based worker and runs the job function
pulled from channel `queue` in a core.async/thread. If that
job returns a fn, puts it back on the `queue` for a worker
to process. Otherwise, worker discards result and repeats."
[queue]
(a/go-loop [job (a/<! queue)]
(try
(when-let [next-state (a/<! (a/thread (job)))]
(when (fn? next-state)
(a/>! queue next-state)))
(catch Exception e
(log/warn "Possible job failure in worker: %s" (.getMessage e))))
(recur (a/<! queue))))
from core.workers namespace
This is a bit more complex than my past examples, but the same idea. We pull a job function off a core.async channel, queue, and execute it. The job function is executed in a core.async thread because jobs must perform blocking network operations. The result, the next-state function comes off the channel returned by thread. Instead of passing the next-state to the next recursive call, next-state returns back to the queue, provided it's a function, so it doesn't starve other job functions waiting in the queue.
Jobs-as-functions also makes for easy synchronous testing as I just wrote a regular (non-go) loop to test each job's FSM. Of course, the jobs themselves require a bit of forethought.
They Took Our Jobs
So what does a job function look like? They're pretty simple:
;; In scinamalink.jobs.domain-verification namespace
(defn finished
[job]
(try
(swap! registry #(dissoc % (:id job)))
(db-jobs/job-finished ds-opts (:id job))
(log/debugf "%s job %s finished" (get-in job [:context :job-type]) (:id job))
(catch Exception e
(do (crashed job)
(log/errorf "Unexpected exception in domain verification finished function: %s"
(.getMessage e))))))
(defn job-work
[job]
(try
(let [{:keys [context]} job
{:keys [customer-id domain-id]} context
domain (db-domains/get-customer-domain-by-id ds-opts customer-id domain-id)
{:keys [verification-code verified domain-name last-checked-at]} domain]
(log/infof "%s job %s checking domain %s"
(get-in job [:context :job-type])
(:id job)
domain-name)
(when-not domain
(throw
(ex-info (str "Customer domain record missing for job " (:id job)) context)))
(if-not verified
(do (db-domains/set-last-checked-at ds-opts customer-id domain-id (Instant/now))
(if (= verification-code (dns/get-domain-text-record domain-name))
(do (log/debugf "setting domain to verified for job %s" (:id job))
(db-domains/set-verified ds-opts customer-id domain-id true))
(log/debugf "no verification code found for job %s" (:id job)))
#(job-work job))
#(finished job)))
(catch Exception e
(do (crashed job)
(log/errorf "error while completing job work: %s" (.getMessage e))
(db-jobs/job-failed ds-opts (:id job) (.getMessage e))))))
(defn do-job
[job]
(try
(swap! registry #(assoc % (:id job) :working))
(let [job (db-jobs/job-working ds-opts (:id job))]
#(job-work job))
(catch Exception e
(do (crashed job)
(log/errorf "job failed: %s %s" job (.getMessage e))
(db-jobs/job-failed ds-opts (:id job) (.getMessage e))))))
(defn start-job
[job]
(try
(swap! registry #(assoc % (:id job) :started))
(let [job (db-jobs/job-started ds-opts (:id job))]
(log/debugf "Starting %s job %s" (get-in job [:context :job-type]) (:id job))
#(do-job job))
(catch Exception e
(do (crashed job)
(log/errorf "job failed in start-job function, job: %s message: %s" job (.getMessage e))
(db-jobs/job-failed ds-opts (:id job) (.getMessage e))))))
(defn ->job
[customer-id domain-id]
(try
(let [job-context {:job-type "domain_verification"
:customer-id customer-id
:domain-id domain-id}
job (db-jobs/create-db-job ds-opts (db-jobs/next-week (Instant/now)) 0 1 job-context)]
(log/info "Domain verification job created")
#(start-job job))
(catch Exception e
(log/warnf "domain verification job failed: %s %s" customer-id domain-id))))from jobs.domain-verification namespace
The domain verification job gets created with ->job which creates the job in the database and returns the first function to place on the queue with something like (dispatch-work queue (->job customer-id domain-id)).
Since the workers are so thin themselves, jobs are responsible for everything related to its function. Each state needs to clean up after itself if something goes wrong. They also update the database with its serialized context regardless of failure.
However, I'm not bound by the rigidity of the job data model though. You'll notice that job-work does most of the work for this task, yet do-job sets the state to :working in the database. I did this because I didn't want to unnecessarily write the state :working to the database each time the job attempts to make the DNS query. The worker doesn't care as long as it gets a function. Although, when the process starts and loads the jobs from the database, it will start at do-job again.
Starting, Restarting, and Unstarting Processes
At some point, jobs will need to be loaded from the database into the worker system whether it's from failures or restarts. This is a pretty simple process: Read from database, dispatch to the appropriate job constructor, and put the resulting jobs on the queue for the workers.
(defmulti ->job-fn
"Multimethod to dispatch on job creation function"
(fn [job]
(let [{:keys [current-state context]} job]
(vector (csk/->kebab-case-keyword (:job-type context))
(keyword current-state)))))
;; Currently in core.worker, but should be in core.loader:
(defn- start-existing-helper!
"Recursively puts each `job` fn on the port `queue`,
presumably to be processed by a worker (see above)."
[queue jobs]
(let [job (first jobs)]
(try
(a/put! queue job (fn [all-good]
(if all-good
(start-existing-helper! queue (rest jobs))
(log/errorf "didn't put job onto queue, exploding: %s" job))))
(catch Exception e
(log/errorf "didn't put job onto queue, exploding: %s" job)))))
(defn start-existing-jobs!
"Starts existing jobs from the DB"
[]
(try
(let [jobs (db-jobs/get-all-pending-jobs ds-opts buffer-limit)]
(->> jobs
(mapv ->job-fn)
(start-existing-helper! queue)))
(catch Exception e
(log/errorf "Unexpected error while starting existing jobs: %s" (.getMessage e)))))In the actual job definition, we can extend ->job-fn with a dispatch values that map to our database record's context column.
(defmethod worker/->job-fn [:domain-verification :created]
[job]
#(start-job job))
(defmethod worker/->job-fn [:domain-verification :starting]
[job]
#(do-job job))
(defmethod worker/->job-fn [:domain-verification :working]
[job]
#(job-work job))
from jobs.domain-verification namespace
This start-existing-jobs! function gets called when the process starts, but we need a method to periodically load jobs while the process is running. Ideally, our job loader would be aware of each running job so that the same jobs aren't loaded over and over.
(defonce registry (atom {}))
;; 1hr = 3600000 ms
(defn loader
"Loads jobs from the Database into the job `w/queue`,
skipping the currently running ones."
[queue ms]
(a/go-loop [to-chan (a/timeout ms)]
(try
(when-not (a/<! to-chan)
(a/<!
(a/thread
(try
(log/debugf "Begin loading jobs from database")
(log/debugf "There are currently %s jobs in the registry" (count (keys @registry)))
(let [jobs (dbw/get-all-pending-jobs ds-opts w/buffer-limit)
running-jobs @registry
stored-jobs (->> jobs
(filterv #(not (contains? running-jobs (:id %))))
(mapv w/->job-fn))]
(doseq [job stored-jobs]
(w/dispatch-work queue job)))
(catch Exception e
(log/warn "Loader exception while loading jobs from DB: %s"
(.getMessage e)))))))
(catch Exception e
(log/warnf "Possible job failure in worker: %s" (.getMessage e))))
(recur (a/timeout ms))))
(defn start-job-loaders!
([queue]
(start-job-loaders! queue 1))
([queue n]
(doseq [_ (range n)]
(loader queue 600000))))core.loader
Lucky for us, core.async violates the thread-local nature of Clojure Vars. Meaning, that I can have a Var pointing to an atom where information about all the running jobs is stored (Jobs take on responsibility of registering themselves). As we can see, a loader functions very similarly to a worker running the start-existing-jobs! functionality, filtering on what's in the registry atom upon this iteration. After each iteration, the loaders will wait using a core.async/timeout for specified amount of time.
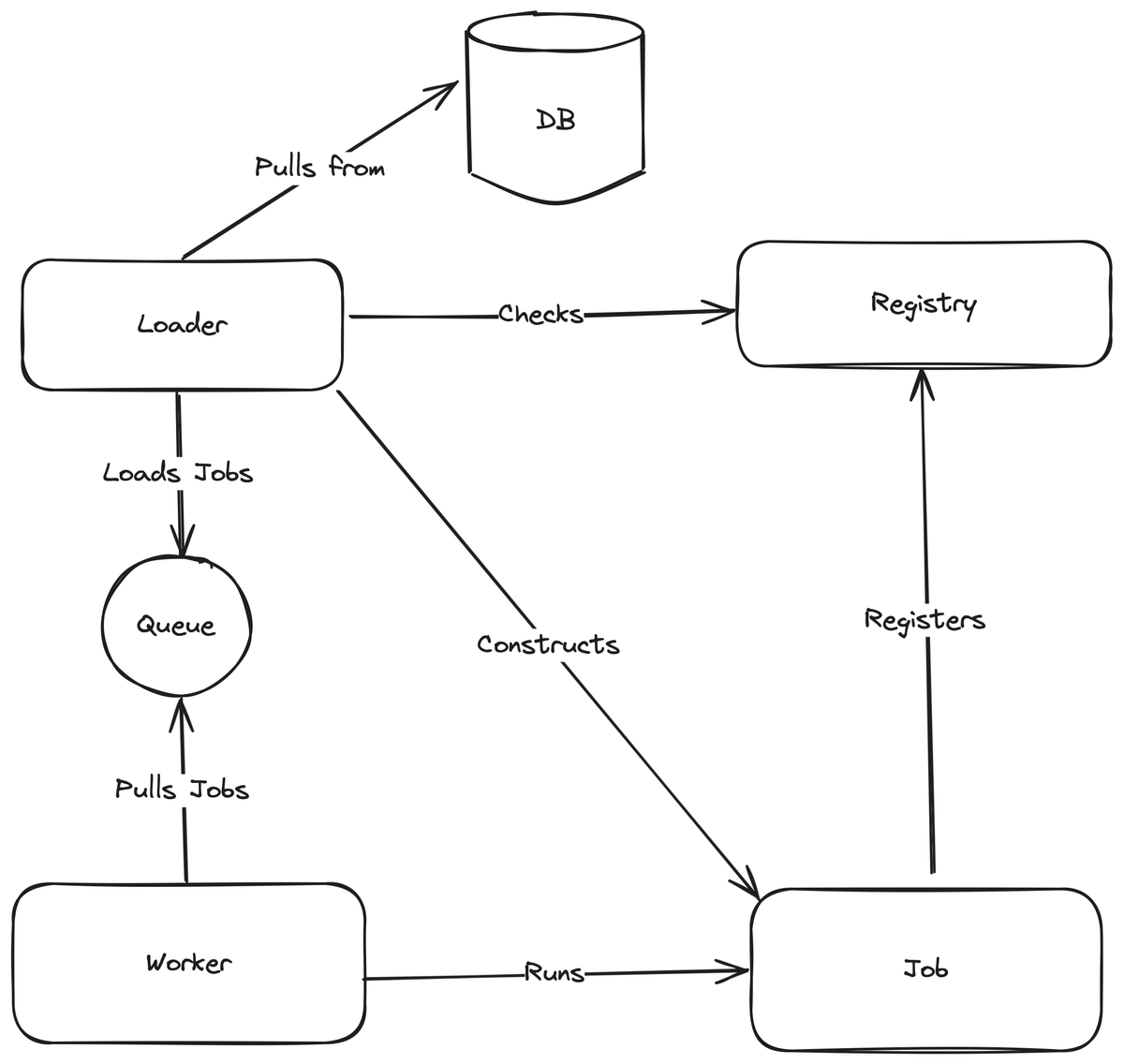
Big Picture
Finally, the big picture of the sub-system emerges.